Airbnb-Daten entschlüsselt: Einblicke und Vorhersagen
Einleitung
Seit 2008 hat Airbnb den Reisemarkt geprägt, indem es Gästen ermöglicht, individuelle Reiseerfahrungen in einzigartigen Unterkünften zu erleben. Im Zentrum dieser Analyse stehen die Airbnb-Angebote in New York City, einem Hotspot des internationalen Tourismus. Das Hauptziel besteht darin, mithilfe des vorliegenden Datensatzes Einblicke in Buchungstrends zu erhalten und zu bestimmen, welche Merkmale zu einer erhöhten Auslastung beitragen.
Die Kernfrage lautet: "Welche Airbnbs in New York City sind am meisten gefragt und weshalb?" Die Antwort darauf bietet nicht nur Einblicke in Gästepräferenzen, sondern liefert auch wertvolle Ratschläge für potenzielle Gastgeber.
Für dieses Projekt setzen wir statistische Datenanalysen und Machine Learning-Modelle mit Python ein, um entscheidende Faktoren für die Buchungsraten herauszuarbeiten. Der Datensatz von Kaggle.com gibt Aufschluss über verschiedene Aspekte der Airbnb-Unterkünfte in New York, einschließlich Stadtteil, Bewertungsfrequenz, Zimmertyp, Preise und Verfügbarkeit über das Jahr.
Zur Beantwortung der Fragestellung greifen wir auf unterschiedliche Methoden zurück: von Datenvisualisierungen über statistische Tests bis hin zur Anwendung des Random Forest-Modells zur Vorhersage der Buchungsfrequenz.
Statistische Datenauswertung
Outlier-Analyse
In der statistischen Analyse unseres Datensatzes war es entscheidend, Ausreißer zu identifizieren und zu behandeln. Ausreißer können das Ergebnis einer Datenanalyse verzerren und zu fehlerhaften Schlüssen führen. Um die Integrität unserer Analyse zu gewährleisten, haben wir sowohl die Z-Score-Methode als auch die IQR-Methode angewendet. Datenpunkte, die von beiden Methoden als Ausreißer identifiziert wurden, wurden aus dem Datensatz entfernt. Dies stellt sicher, dass unsere nachfolgende Analyse auf einem bereinigten Datensatz basiert, der repräsentativ für die allgemeinen Trends und Muster im Airbnb-Markt von New York City ist.
Multivariate Analyse
Die multivariate Analyse zielt darauf ab, die Beziehungen zwischen mehreren Variablen gleichzeitig zu verstehen und zu interpretieren. Eine der effektivsten Techniken, um diese Art von Beziehung in einem Datensatz zu visualisieren, ist die Heatmap. Die vorgelegte Heatmap zeigt die Korrelationskoeffizienten zwischen den Variablen unseres Airbnb-Datensatzes.
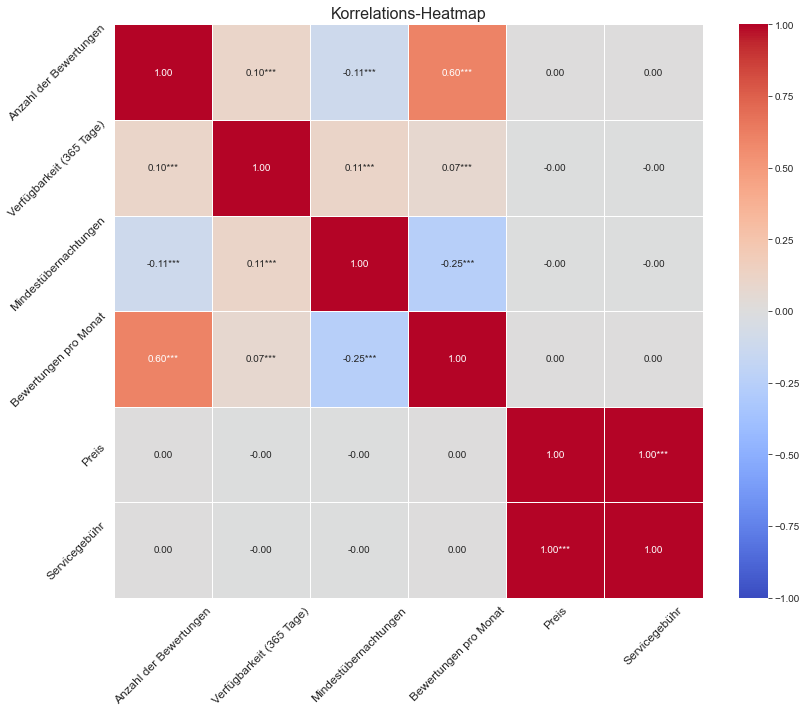
Aus der Heatmap und unter Verwendung des Pearson-Korrelationskoeffizienten, der lineare Beziehungen misst, können wir folgende Schlüsselbeobachtungen ableiten:
Es gibt eine starke positive Korrelation (0.60) zwischen der "Anzahl der Bewertungen" und der "Verfügbarkeit (365 Tage)", was darauf hindeutet, dass Unterkünfte, die häufiger verfügbar sind, auch mehr Bewertungen erhalten.
"Bewertungen pro Monat" und "Anzahl der Bewertungen" weisen ebenfalls eine positive Korrelation (0.07) auf, obwohl diese Beziehung weniger stark ausgeprägt ist.
Interessanterweise gibt es eine negative Korrelation (-0.25) zwischen "Bewertungen pro Monat" und "Mindestübernachtungen", was darauf hindeutet, dass Unterkünfte, die längere Mindestaufenthalte erfordern, tendenziell weniger Bewertungen pro Monat erhalten.
Es gibt keine signifikante Korrelation zwischen "Preis" und anderen Merkmalen, was darauf hindeutet, dass der Preis unabhängig von Faktoren wie Verfügbarkeit, Mindestaufenthalt oder Anzahl der Bewertungen festgelegt wird.
"Servicegebühr" zeigt auch keine signifikante Korrelation zu anderen Merkmalen.
Statistische Tests
Untersuchungen wurden durchgeführt, um festzustellen, ob es signifikante Unterschiede in der Verfügbarkeit über 365 Tage zwischen verschiedenen Gruppen von Unterkünften auf Airbnb gibt.
Vergleich zwischen Gastgebern mit verifizierter Identität und denen ohne Verifizierung: Ein T-Test wurde durchgeführt, um den Durchschnitt der Verfügbarkeit zwischen Gastgebern, deren Identität verifiziert wurde, und denen, die unbestätigt sind, zu vergleichen. Die Ergebnisse zeigen, dass es keinen signifikanten Unterschied im Durchschnitt der Verfügbarkeit zwischen den beiden Gruppen gibt, t(82209) = -1.645, p = .1. Dies deutet darauf hin, dass die Überprüfung der Identität eines Gastgebers keinen Einfluss auf die Verfügbarkeit ihrer Unterkunft hat.
Einfluss des Zimmertyps auf die Verfügbarkeit: Eine ANOVA-Untersuchung wurde durchgeführt, um den Einfluss des Zimmertyps auf die Verfügbarkeit zu analysieren. Die Ergebnisse zeigen eine sehr signifikante Wirkung des Zimmertyps auf die Verfügbarkeit, F(3, 82209) = 47.227, p < .001. Dies legt nahe, dass einige Zimmertypen durchschnittlich häufiger oder seltener verfügbar sind als andere.
Einfluss der Stornierungsrichtlinie auf die Verfügbarkeit: Eine weitere ANOVA-Untersuchung wurde durchgeführt, um den Einfluss der Stornierungsrichtlinie auf die Verfügbarkeit zu analysieren. Die Ergebnisse zeigen, dass die Stornierungsrichtlinie keinen signifikanten Einfluss auf die Verfügbarkeit hat, F(2, 82156) = 0.067, p = .935. Dies bedeutet, dass unabhängig von der Stornierungsrichtlinie, die ein Gastgeber für seine Unterkunft gewählt hat, die durchschnittliche Verfügbarkeit über das Jahr hinweg relativ konstant bleibt.
ML-Modellierung
Die ML-Modellierung zielt darauf ab, ein Machine Learning-Modell zu entwickeln, das die Verfügbarkeit von Unterkünften auf Airbnb über 365 Tage basierend auf bestimmten Merkmalen vorhersagen kann. Für dieses Projekt wurde das Random Forest Regressionsmodell gewählt, ein Ensemble-Lernansatz, der mehrere Entscheidungsbäume kombiniert, um eine robustere und genauere Vorhersage zu erreichen.
In unserer Analyse haben wir uns darauf konzentriert, den Einfluss bestimmter Merkmale auf die Verfügbarkeit von Unterkünften auf Airbnb über das ganze Jahr hinweg zu untersuchen. Als Eingangsmerkmale wurden "Zimmertyp", "Bewertungen pro Monat", "Mindestübernachtungen" und "Preis" ausgewählt.
Der "Zimmertyp" gibt Auskunft über die Art der angebotenen Unterkunft, sei es ein ganzes Haus, eine private Wohnung oder ein gemeinsam genutztes Zimmer. Da dieses Merkmal kategorial ist, wurde es in numerische Werte umgewandelt, um es in das Modell zu integrieren.
"Bewertungen pro Monat" bieten Einblicke in die Popularität einer Unterkunft. Eine hohe Anzahl von monatlichen Bewertungen könnte darauf hindeuten, dass eine Unterkunft häufiger gebucht wird, was sich auf ihre Verfügbarkeit auswirken könnte.
"Mindestübernachtungen" geben die Anzahl der Nächte an, die ein Gast mindestens buchen muss. Dieses Merkmal kann wichtige Informationen darüber liefern, wie der Gastgeber den Aufenthalt in seiner Unterkunft sieht, ob er kürzere, häufigere Buchungen oder längere Aufenthalte bevorzugt.
Schließlich spiegelt der "Preis" den Betrag wider, den Gäste pro Nacht zahlen müssen. Dies könnte ein Indikator für die Qualität, Lage oder Beliebtheit der Unterkunft sein.
Diese Merkmale wurden ausgewählt, da sie alle wesentliche Aspekte des Buchungserlebnisses auf Airbnb repräsentieren und direkt die Verfügbarkeit einer Unterkunft beeinflussen können.
Modelltraining und -optimierung
Für die Optimierung unseres Random Forest-Modells haben wir den GridSearchCV-Ansatz angewendet. Hierbei haben wir systematisch verschiedene Anzahlen von Entscheidungsbäumen getestet, um die optimale Anzahl zu ermitteln. Ziel war es, die Konfiguration zu finden, die im Rahmen der Kreuzvalidierung den geringsten durchschnittlichen quadratischen Fehler (MSE) erzielt. Dieser Schritt gewährleistet, dass unser Modell so genau wie möglich Vorhersagen trifft.
Ergebnisse im Überblick
Durchschnittlicher Quadratfehler (MSE): 12581.294 Der MSE misst, wie dicht die Vorhersagen unseres Modells an den tatsächlichen Daten liegen. Ein geringerer MSE signalisiert ein treffsicheres Modell. Bei uns bedeutet dies, dass es im Durchschnitt eine quadratische Abweichung von 12581.294 zwischen den Prognosen und den realen Daten gibt.
Durchschnittlicher Fehler (RMSE): 112.167 Der RMSE stellt den durchschnittlichen Fehler dar und ist in diesem Fall besonders aussagekräftig, da er in den gleichen Einheiten gemessen wird wie unsere Zielvariable - der Verfügbarkeit in Tagen. Unsere Vorhersagen liegen also durchschnittlich 112 Tage von den realen Werten entfernt.
Bestimmtheitsmaß (R^2): 0.288 Der R^2 gibt uns Aufschluss darüber, wie gut unser Modell die tatsächlichen Schwankungen in den Daten erfasst. Mit einem Wert von 0.288 zeigt unser Modell, dass es in der Lage ist, etwa 28,8% der Schwankungen in der Verfügbarkeit der Zimmer zu erklären. Dies ist ein Hinweis darauf, wie viel des Gesamtverhaltens der Daten durch unser Modell verstanden wird.
Feature-Wichtigkeiten:
Preis: 0.540
Reviews pro Monat: 0.336
Mindestnächte: 0.089
Zimmertyp: 0.035
Die Feature-Wichtigkeiten zeigen die relative Bedeutung jedes Merkmals für die Vorhersagen des Modells an. Hier zeigt sich, dass der Preis das wichtigste Merkmal ist und allein etwa 54% der Wichtigkeit in den Vorhersagen ausmacht. Die Anzahl der Bewertungen pro Monat ist mit 33,6% ebenfalls sehr wichtig. Mindestnächte und Zimmertyp sind weniger wichtig, tragen aber immer noch zur Gesamtvorhersage bei.
Interpretation
Das entwickelte Random Forest-Modell konnte einen Teil der Variabilität in der Verfügbarkeit von Unterkünften auf Airbnb über 365 Tage erklären, wobei es jedoch Raum für Verbesserungen gibt.
Der Preis hat sich als das dominanteste Merkmal herausgestellt. Dies könnte bedeuten, dass Unterkünfte mit einem höheren Preis häufiger verfügbar sind. Möglicherweise liegt dies daran, dass diese Unterkünfte für den durchschnittlichen Reisenden weniger erschwinglich sind und daher seltener gebucht werden. Ein weiterer Grund könnte sein, dass solche teureren Unterkünfte über besondere Annehmlichkeiten oder Einzigartigkeiten verfügen, die einen spezifischeren Markt ansprechen, wodurch sie nicht ständig ausgebucht sind. Es ist auch möglich, dass Gastgeber, die ihre Unterkünfte zu einem höheren Preis anbieten, flexiblere Buchungsbedingungen haben, wodurch sie öfter verfügbar sind.
Die Anzahl der Bewertungen pro Monat, die das zweitwichtigste Merkmal war, gibt einen Hinweis auf die Popularität der Unterkunft. Eine höhere Anzahl von Bewertungen könnte bedeuten, dass die Unterkunft häufiger gebucht wird, was wiederum ihre Verfügbarkeit beeinflussen könnte. Interessanterweise ist dies bedeutender als die Mindestnächte, was darauf hinweist, dass die Länge des Aufenthalts nicht unbedingt einen größeren Einfluss auf die Verfügbarkeit hat als die Häufigkeit der Buchungen.
Der Zimmertyp, obwohl er das am wenigsten wichtige Merkmal war, spielt immer noch eine Rolle. Verschiedene Zimmertypen könnten unterschiedliche Zielgruppen von Reisenden anziehen. Zum Beispiel könnten ganze Wohnungen oder Häuser von Familien oder Gruppen bevorzugt werden, die für längere Zeiträume bleiben, während private Zimmer eher von Einzelreisenden für kürzere Aufenthalte gebucht werden könnten.
Abschließend zeigt dieses Modell, dass, obwohl einige Faktoren stärker zur Vorhersage der Verfügbarkeit beitragen als andere, eine Kombination von Merkmalen erforderlich ist, um eine genauere Vorhersage zu treffen. Zukünftige Modelle könnten von weiteren Daten, wie zum Beispiel der Lage der Unterkunft, der Anzahl der Schlafzimmer oder der Annehmlichkeiten, profitieren. Es wäre auch interessant zu untersuchen, wie saisonale Faktoren oder Veranstaltungen in der Nähe der Unterkunft die Verfügbarkeit beeinflussen könnten.
Zusätzliche Ressourcen und tieferer Einblick
Für diejenigen, die sich tiefer in die technischen Details dieser Analyse einarbeiten möchten oder Interesse daran haben, die von mir verwendeten Codes und Daten selbst zu überprüfen, lade ich herzlich ein, mein GitHub-Repository zu besuchen. Dort finden Sie alle Skripte, Datenvisualisierungen und zusätzlichen Informationen, die für dieses Projekt verwendet wurden. Klicken Sie einfach auf den folgenden Link: Airbnb Datenanalyse auf GitHub.